基于原论文和kaggle实践的LIME可解释机器学习方法学习笔记
论文标题为: “Why Should I Trust You?” Explaining the Predictions of Any Classifier
为什么要打开黑盒?
要为甲方提供更好的服务,最重要的一点就是要取得其信任。所以想要部署一个模型,必须要让模型可信。特别是在自动驾驶、医疗等人命关天的领域,回答“为什么要信任你”对于机器学习从业者是一个巨大的问题。
论文中提到两个取得信任的重要点:
- 如何相信结果的可靠性。用户是否能相信模型的结果能提供有效帮助。
- 如何相信模型的可靠性。用户是否能相信模型能合理的运行。
就和开八卦一样。64个卦象,512爻。能读懂“象”,也就是结果,只是第一步。而能弄懂周易中万物的运行规律,你才能取得真正的收获。无脑相信很容易调入江湖方士的陷阱,能正确有逻辑的解释才能有所启发。
几个月前,我还刷到视频说可解释机器学习是纯纯的瞎扯,打开黑盒模型是一件徒劳无功的事情。机器学习发展到如今的应用层面,不能无脑的相信,而是应该去理解和解释,所以说追求可解释性已经是一件势在必行的事情了。
另外,每个完整的机器学习流程中都应该包括模型理解和解释。有以下原因$^{[1]}$:
- 模型改进。仅仅凭借metric来选择模型算法是不可信的,因为测试数据可能会
- 模型可信性与透明度。让黑箱模型来决定人们的生活是不现实的。
- 识别和防止偏差。
案例$^{[4]}$
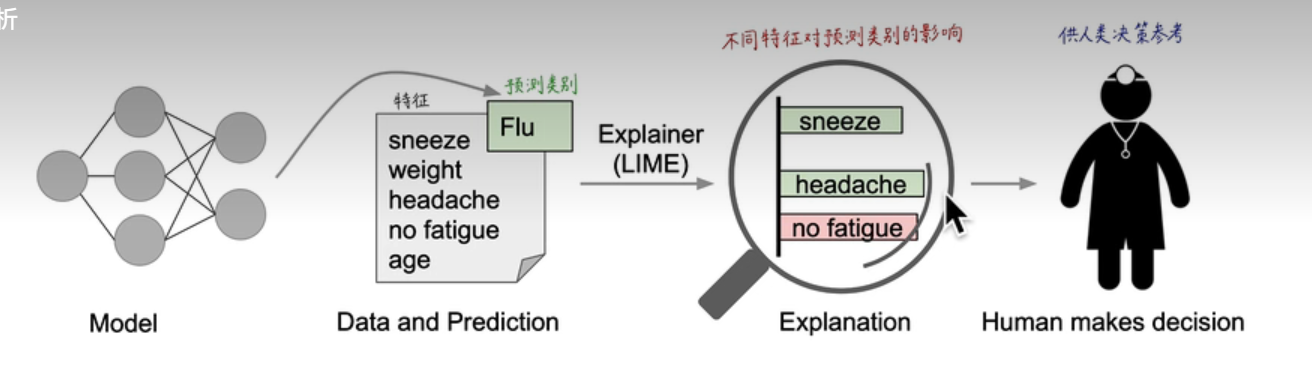
一个模型预测了一个患者患有流感,而LIME识别出该患者的病史中导致该预测的症状特征。打喷嚏和头痛被描述为对“流感”的预测依据,而“不疲劳”则是相反的证据。有了这些方法,医生就可以明智地决定是否信任模型的预测。
针对人工智能的底层问题OOD泛化,也就是论文中的data shift。论文中提到可以使用可解释性方法提供的信息来解决上述问题$^{[3]}$。
The insights given by explanations are particularly helpful in identifying what must be done to convert an untrustworthy model into a trustworthy one – for example, removing leaked data or changing the training data to avoid dataset shift.
LIME:Local Interpretable Model-agnostic Explanations的基本原理
一句话概括LIME:使用可解释特征训练可解释模型,在特定样本的局部线性邻域拟合原模型。
LIME 的核心在于三个方面$^{[1]}$:
- 这里不对模型整体提供解释,而是局部对某一个样本单独进行解释;
- 即使机器学习模型训练过程会产生一些抽象的特征,但是解释只基于当前输入数据的变量特征
- 通过局部建立简单模型进行预测来对大多数重要特征进行解释。
比如复杂模型会使用各种分子描述符作为输入特征,而可以指定某几种重要的特征作为可解释模型的输入。
LIME算法步骤$^{[3]}$
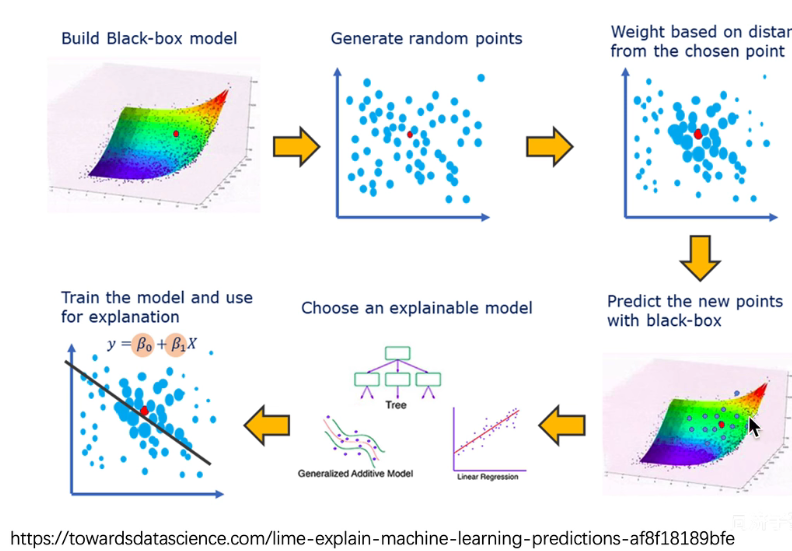
- 训练一个机器学习模型(ML)和选出一个具有代表性的数据点(X)。
- 这个ML可以是复杂的,解释性差的。
- 我们选出的X是原数据集中具有代表性且非冗余的。(representable and non-redundent individual predictions.)
- 在X周围生成一些数据点${x_{i}} \in \mathbb{R}^{p}$,此步骤称为Generate Step
- 使用ML模型获得生成的数据点的标注Y。
- Because the Y is computed using the ML model, we are guaranteed that the new points perfectly lie on the ML surface!
- 这样就获得了一个由生成的数据${x_{i}}$和ML标注$Y_i$组成的数据集。
- 根据与选定点X的接近程度,指定生成点${x_{i}}$的权重。
- 比如使用FBF核函数,让和中心点接近的点获得更大的权重。
- 在生成的数据集上训练一个可解释性好的模型,比如线性回归:$E(Y) = \beta_0 + \sum \beta_iX_i$。其中的系数$\beta$则是解释模型的依据。
所以LIME的解释只在某一点的邻域有效,而此邻域的范围也是值得讨论的问题。
Generation Step
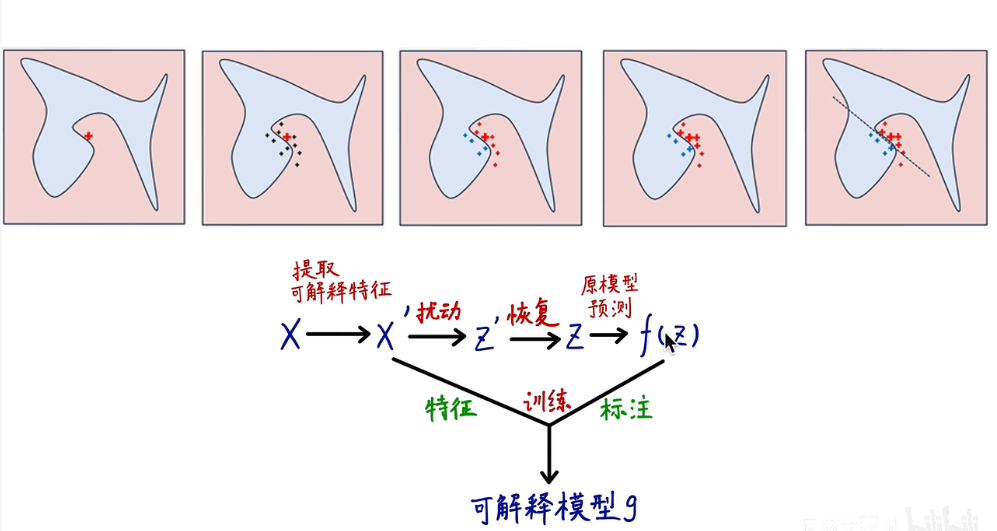
LIME在某一参考点$x$周围生成了n个数据集点${x_{i}’} \in \mathbb{R}^{p}$。也就是第二张图中,红点周围的灰色的数据点。
如何生成数据点呢?这取决于数据的类型(文本、图像或表格数据)。对于文本和图像,解决方案是打开或关闭单个单词或超像素。对于表格数据,LIME通过逐个扰动每个特征来创建新样本,或者permutation(置换) ,从每个特征中提取的均值和标准差绘制正态分布$^{[2]}$。
这里只是生成了数据点的特征,和原数据集中的数据点不同,这些生成的数据点并没有标签。此时我们使用原模型$f$获得 $x’$的标签 $\widehat{y} =f(x’)$。
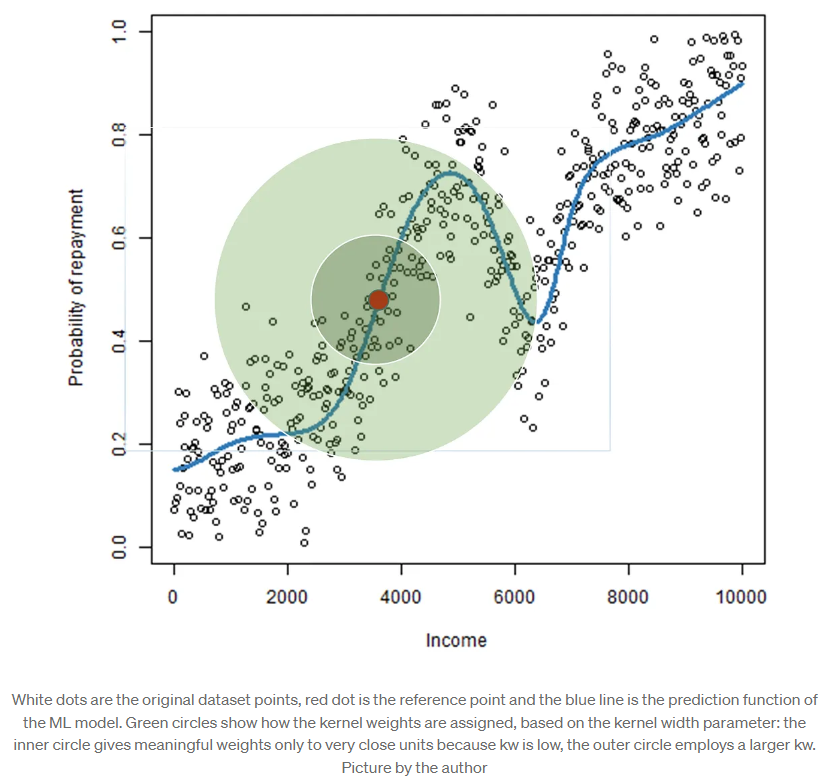
因为LIME是一个获得局部解释的方法,我们可以ingore和参考点距离较远的数据点,所以可以使用高斯核函数的方法对每一个点估计一个权重。
$$ RBF(x^{(i)}) = exp(- \frac{||x^{(i)} - x^{(ref)}||}{kw}) $$
高斯核得到的值在[0,1]范围内,越高则越接近参考点。核宽度$kw$参数决定红点周围有权重的圆有多大。
Local Explainable Model Step
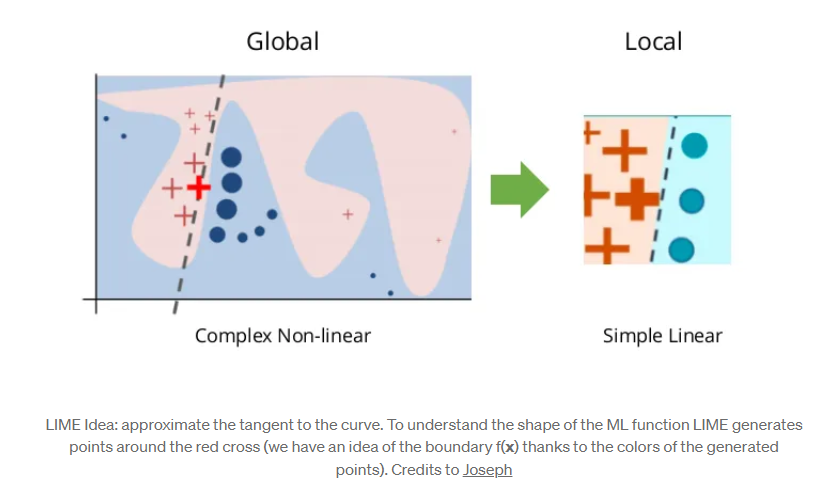
在得到的生成数据集上,建立局部的可解释性模型。这个模型有很多选择,比如(Decision Trees, Logistic Regression, GLM, GAM, etc),在LIME的python库中默认是Ridge Regression也就是岭回归。在选择可解释性模型时,需要权衡可解释性和拟合能力。
Advantages of LIME$^{[3]}$
- 此方法是model_agnostic(和模型无关)的。所以你即使替换了底层的机器学习模型,你也可以使用同一种可解释模型对其进行解释。
- 当使用简单的可解释模型,比如Lasso or short trees时,生成的解释是简洁而有重点的,可能会强调不同特征之间的对比,这是一种Human-friendly的表达。但是也不能获得完全严格的解释结果,这使LIME在解释的受众是普通人或者那些时间有限的人的应用中更常见。
- LIME是适用于表格数据(tabular data)、文本和图像的少数几种解释机器学习方法之一。
- LIME可以在Python(lime库)中轻松使用。
- 局部可解释模型可以使用与原始模型训练时不同的可解释特征,但这些特征必须来自数据实例。这使得当模型是使用不可解释特征进行训练时,LIME可以使用可解释特征。
Weak Points of LIME
Ignoring the Correlation between Features$^{[2]}$
当前的LIME实现中,采样过程可以进一步改进。数据点是从高斯分布中采样的,而不考虑特征之间的相关性,这可能导致不太可能的数据点用于学习本地解释模型。
The Instable of LIME$^{[2]}$
解释的不稳定性是另一个大问题,即相近的数据点的解释可能会出现很大变化。不稳定性使得难以信任解释,需要对其持高度批判性的态度。
LIME explanations can be manipulated$^{[2]}$
有论文指出:LIME的解释可以被数据科学家操控以隐藏偏差,这使得更难相信LIME生成的解释。
如何定义邻域?$^{[3]}$
在generate step中,在参考点$x$周围生成了n个数据集点${x_{i}’} \in \mathbb{R}^{p}$,然后使用具有适当核宽度(Kernel Width)的RBF,让局部可解释模型更关注那些距离较近的点。
所以说,正确定义邻域(neighborhood)是一个非常重要且尚未解决的问题$^{[3]}$,因为邻域的大小变化会影响局部可解释模型。这是LIME最大的问题,对于每次应用,都需要尝试不同的核设置,并且亲自验证解释是否合理。
Why don’t just generate points close to the reference?$^{[3]}$
这是一个微妙的问题:原则上,最好只考虑感兴趣区域内的数据点,尽管这个区域的适当大小不是固定的,而是取决于参考点。
事实上,邻域应该包括参考点周围机器学习曲线的全部线性区域,因此它取决于 f(x) 的局部曲率。
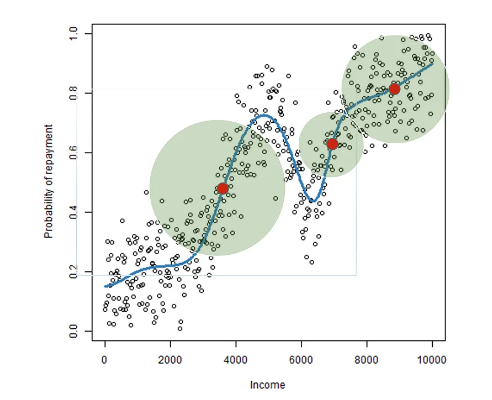
关于LIME的局部数据生成技术,已经有一些研究,尤其是Laugel和Renard的工作以及Guidotti的LORE技术。不幸的是,它们两者仍存在一些问题。第一篇论文在方法中考虑了其他因素,但忽略了切线这一重要概念。而第二篇论文则不能保证考虑参考点周围的整个线性区域(它只找到一个非常小的邻域,而没有检查ML函数是否在稍远处也是线性的)。这是一个很大的缺陷,因为小邻域会导致LIME的解释不稳定(unstable)。
How to choose the correct value for the kernel width?
如果对于每次应用,都需要尝试不同的核设置,并且亲自验证解释是否合理,会造成一种矛盾。简述如下:
有时我们不确定机器学习模型是否做出了合理的决策。因此,如果机器学习模型找到奇怪或不合理的规则,我们期望LIME也会变得不合理(毕竟这正是我们使用LIME的原因:为了理解机器学习的行为和潜在问题)。如果有不合理的地方,我们可以及时回到模型训练阶段予以纠正,毕竟越晚发现问题,纠错成本就越大。
如果我们基于有意义的解释来选择 kw 值,那么我们将无法发现任何机器学习模型的问题!!
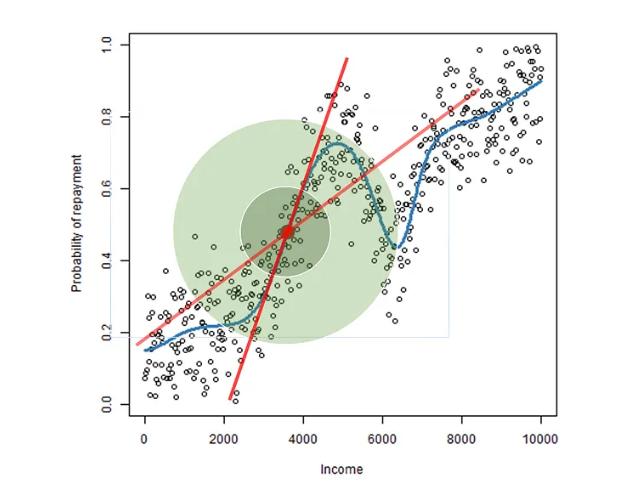
最近一个新的框架OptiLIME被提出,用于找到最佳的核宽度,以确保LIME的解释能够代表机器学习曲线的切线。开源实现可以在Github上找到。
参考资料
【1】可解释性机器学习综述
【2】Interpretable Machine Learning
【3】LIME: explain Machine Learning predictions
【5】Local Interpretable Model-Agnostic Explanations (LIME): An Introduction
【6】lime python库
【7】Explainable Machine Learning
【8】Instability of LIME Explanations
文本分类的例子
文本二分类实践,lime官方demo
1 | import lime |
获取数据,训练分类器
For this tutorial, we’ll be using the 20 newsgroups dataset. In particular, for simplicity, we’ll use a 2-class subset: atheism(无神论) and christianity(基督教).
1 |
|
Let’s use the tfidf vectorizer, commonly used for text.
TF-IDF(Term Frequency-Inverse Document Frequency)是一种文本向量化技术,用于表示文档中的单词或短语在语料库中的重要性。
TF-IDF向量化器会为每个文档中的每个词项生成一个向量,其中包含了文档中各个词项的TF-IDF权重。这些向量可以被用作文本数据的特征,输入到机器学习模型中,以进行各种文本分析任务,如文本分类、信息检索、聚类等。
1 | vectorizer = sklearn.feature_extraction.text.TfidfVectorizer(lowercase=False) |
Now, let’s say we want to use random forests for classification. It’s usually hard to understand what random forests are doing, especially with many trees.
1 | rf = sklearn.ensemble.RandomForestClassifier(n_estimators=500) |
0.9187935034802783
We see that this classifier achieves a very high F score. The sklearn guide to 20 newsgroups indicates that Multinomial Naive Bayes overfits this dataset by learning irrelevant stuff, such as headers. Let’s see if random forests do the same.
使用LIME来解释结果
Lime explainers assume that classifiers act on raw text, but sklearn classifiers act on vectorized representation of texts. For this purpose, we use sklearn’s pipeline, and implement predict_proba on raw_text lists.
Lime解释器假定处理原始文本,但Scikit-Learn的分类器处理文本的向量表示。因此,我们使用Scikit-Learn的管道(pipeline),并在原始文本列表上实现predict_proba。
1 | from sklearn.pipeline import make_pipeline |
1 | print(c.predict_proba([newsgroups_test.data[0]])) |
[[0.274 0.726]]
Now we create an explainer object. We pass the class_names as an argument for prettier display.
1 | from lime.lime_text import LimeTextExplainer |
We then generate an explanation with at most 6 features for an arbitrary document in the test set.
1 | idx = 83 |
Document id: 83
Probability(christian) = 0.47
True class: atheism
The classifier got this example right (it predicted atheism).
The explanation is presented below as a list of weighted features.
1 | exp.as_list() # 以一列加权特征的形式呈现解释。 |
[('Host', -0.14415916430975254),
('NNTP', -0.10713334123095371),
('Posting', -0.1062025037463582),
('edu', -0.025935273142425563),
('There', -0.017081550442702414),
('anyone', 0.014256959274182798)]
These weighted features are a linear model, which approximates the behaviour of the random forest classifier in the vicinity of the test example. Roughly, if we remove ‘Posting’ and ‘Host’ from the document , the prediction should move towards the opposite class (Christianity) by about 0.27 (the sum of the weights for both features). Let’s see if this is the case.
这些加权特征构成了一个线性模型,该模型在测试示例附近近似了随机森林分类器。
进一步,如果我们从文档中移除 ‘Posting’ 和 ‘Host’ 这两个特征,预测应该朝着相反的类别(Christianity)移动,大约移动了0.27个单位(这是这两个特征权重的总和)。让我们看看是否确实如此。
1 | print('Original prediction:', rf.predict_proba(test_vectors[idx])[0, 1]) |
Original prediction: 0.47
Prediction removing some features: 0.696
Difference: 0.22599999999999998
Pretty close!
The words that explain the model around this document seem very arbitrary - not much to do with either Christianity or Atheism.
In fact, these are words that appear in the email headers (you will see this clearly soon), which make distinguishing between the classes much easier.
非常接近!
解释模型在这个文档周围的单词似乎非常随意,与基督教或无神论没有太大关系。
实际上,这些是出现在电子邮件标题中的单词(您很快会清楚地看到这一点),这些单词使得区分不同类别变得更容易。
Visualizing explanations
The explanations can be returned as a matplotlib barplot:
1 | %matplotlib inline |

1 | exp.show_in_notebook(text=False) |
That’s it for this tutorial. Random forests were just an example, this explainer works for any classifier you may want to use, as long as it implements predict_proba.